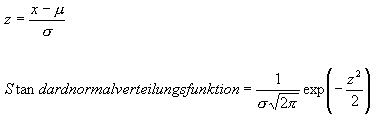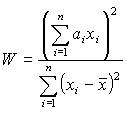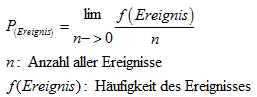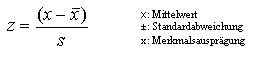|
Lexikon | |||||
Sprung zum Bereich: | ||||||||||||||
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z Literaturstellen Links | ||||||||||||||
ABC-Analyse siehe hier! | ||||||||||||||
Abbildung, Zuordnungsvorschrift für Elemente von Mengen | ||||||||||||||
Absolutbetrag | ||||||||||||||
Abszisse: Bezeichnung für die “horizontale” Koordinate des kartesischen Koordinatensystems (x-Achse). | ||||||||||||||
Abweichung (deviation, error): Ist die Abweichung zwischen einem Merkmalswert und einem Bezugswert des Merkmals. | ||||||||||||||
AIC (An Information Criterion) siehe hier! | ||||||||||||||
Analysenprobe siehe Messprobe | ||||||||||||||
Analytische Sensitivität (Empfindlichkeit) (analytical sensitivity): Sie beschreibt die Fähigkeit einer Prüfmethode zwischen z. B. konzentrationsabhängigen Signalen zu differenzieren (Steigung einer Kalibrierfunktion). | ||||||||||||||
Analytische Spezifität (analytical specifity): Ist die Fähigkeit einer Prüfmethode, nur die gesuchte Substanz zu erfassen, wobei andere Bestandteile der Matrix das Prüfergebnis nicht beeinflussen. | ||||||||||||||
Angepasstes Bestimmtheitsmaß r2 (Adjusted r2) siehe hier! | ||||||||||||||
Annahmeprüfung: Qualitätsprüfung zur Feststellung, ob ein Produkt wie bereitgestellt oder geliefert annehmbar ist. | ||||||||||||||
ANOVA: analysis of variance / Varianzanalyse, mehr dazu hier....! |
Anti-Image-Kovarianz-Matrix: Dient zur Eignungsprüfung einer Korrelationsmatrix in der Faktorenanalyse, mehr dazu hier! | |||||
arbitrary origin: willkürlicher Nullpunkt | |||||
Assoziativgesetz: (siehe auch Kommutativgesetz) (a+b)+c = a+(b+c) (a*b)*c = a*(b*c) | |||||
Audit (Qualitästaudit): Ein Qualitätsaudit, kurz Audit (lat. audire = (an)hören), ist eine systematische und objektive Untersuchung auf Erfüllung von Qualitätsanforderungen (siehe ISO 9000:2000 ff.). Das Ziel eines Audits ist | |||||
|
Es wird in 3 Auditarten unterschieden: |
|
Und es wird auch danach unterschieden, wer das Audit durchführt: |
|
Ausreissertest, siehe Extremwert |
Aussage: Eine Aussage ist ein feststellender Satz, dem eindeutig einer der beiden Wahrheitswerte wahr oder falsch zugeordnet werden kann. |
Ein Axiom (Postulat) ist eine Aussage, die von vornherein als wahr vorausgesetzt wird und nicht bewiesen werden kann. Sie stellen das Fundament dar, auf dem mathematische Theorien aufbauen. |
Bartlett-Sphärentest findet Verwendung in der Eignungsprüfung der Korrelationsmatrix in der Faktorenanalyse. |
Bartlett-Test auf Gleichheit mehrerer Varianzen bei gleichem oder unterschiedlichen Stichprobenumfängen. | ||||||
Befragung siehe Primär- und Sekundärstatistik | ||||||
Beobachtung siehe Primär- und Sekundärstatistik | ||||||
- Funktionen, -Intervalle | ||||||
Beschreibende Statistik oder gleich deskriptive Statistik... | ||||||
Bestimmungsgrenze: siehe Nachweisgrenze |
Als Bias oder auch Verzerrung, wird der systematische Einfluss auf erhobene Daten genannt. Das bedeutet, dass die durchgeführten Schätzungen ein konstantes zu hohes oder zu niedriges Resultat zeigen. Ursachen dieser Verzerrung können sein:
|
Big Data, in Verbindung mit Data Mining siehe hier! | |||||
Bijektivität, siehe hier! | |||||
Hinweise zu Bindungen in Datenerhebungen finden Sie hier! | |||||
Blindwert (siehe auch Richtigkeit) |
Der Begriff BLUE steht im Zusammenhang mit der Regressionsanalysen und beschreibt die Voraussetzungen, damit die Schätzung der Regressionsanalyse die bestmöglichen Ergebnisse liefert. Unter folgenden Voraussetzungen werden die Koeffizienten der Regressionsanalyse als BLUE (der beste, lineare, unverzerrte und effizienteste Schätzer) bezeichnet:
Unverzerrt bedeutet, dass der Erwartungswert der Koeffizienten den wahren Werten der Koeffizienten der Grundgesamtheit entspricht. Effizient bedeutet, dass die Koeffizienten mit der kleinstmöglichen Streuung geschätzt werden. | |||
Bogenmaß, Beziehung Grad und Bogenmaß (Radiant, rad) | |||
Charge: Begriffe zur Probenahme |
Chemometrie: Chemometrie ist der Teil der chemischen Disziplinen, der mathematische und statistische Methoden zur Auswahl optimaler Messverfahren, zur Plannung von Experimenten und zur Gewinnung maximaler Informationen bei der Analyse der erhaltenen Daten verwendet. |
Chiquadrat-Test, Der | ||
Clusteranalyse siehe Multivariate Analysenmethoden | ||
Über den Cohen’s d kann die Effektstärke für unabhängige Stichproben geschätzt werden. Dieser Test bietet sich im Nachgang zum t-Test an. Die Prüfgröße d ist die Mittelwertdifferenz der Beobachtungen normiert über die Standardabweichungen:
Zur Interpretation und Vergleichbarkeit führte Cohen diese Einteilung ein: d = 0,2 geringer / kleiner Effekt Ein Beispiel für einen sehr staken Effekt: Mittelwert1: 98,133, Standardabweichung1: 0,294, Anzahl Beob.1: 15
|
Conjoint Measurement siehe Multivariate Analysenmethoden |
cp- und cpk-Index: Die Prozessfähigkeit wird neben weiteren, durch die Indices cp, process capability, und durch cpk, critical process capability, beschrieben. Mehr dazu und die Berechnung finden Sie hier....! |
Eine Übersicht über das Thema Data Mining finden Sie hier und das erwähnte Data-Mining- Projekt-Modell CRISP-DM 1.0 können Sie über diesen Link auf Ihren Computer laden! |
Sind die Daten zur statistischen Betrachtung schon vorhanden, wird von einer Erhebung gesprochen. Es werden folgende Erhebnungsarten unterschieden: | ||||
| ||||
Diagnosemethoden (Psychologie): | ||||
| ||||
Diskriminanzanalyse siehe Multivariate Analysenmethoden oder hier...! | ||||
Beschreibende Statistik durch graphische Aufbereitung und Komprimierung (z. B. Mittelwert und Streuung) von Daten (siehe auch explorative und induktive Statistik). |
Dispersionsmaße: Maße, die die Variabilität der Verteilung kennzeichnen, wie z. B. Standardabweichung oder Spannweite. |
e (Euler’sche Zahl): Der Grenzwert der Funktion ... |
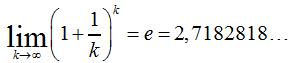 |
... ist die e-Zahl, oder auch nach Leonhard Euler Euler’sche Zahl genannt. Die e-Zahl ist häufig die Basis für Wachstumsprozesse in der Natur und wird deswegen als natürliche Basis bezeichnet. Als Beispiel sei hier das Bakterienwachstum genannt: |
Einfach ausgedrückt, sind Effekte für die wir uns interessieren fixed effects (oder auch feste Faktoren) und Faktoren die in unseren Beobachtungen enthalten sind, für die wir uns weniger interessieren, random effects (oder auch Zufallsfaktoren). Die gebildete Hypothese entscheidet letztendlich, was für den Prüfer ein fixed oder random effect ist. | |||
Effektstärke: - Cohen’s d, siehe hier! |
Eichen (verification): Das Eichen eines Messgerätes umfasst die von der zuständigen Eichbehörde nach den Eich- vorschriften vorzunehmenden Prüfungen und die Stempelung. (DIN 1319 Teil1) | ||||||||
Eingangsprüfung (receiving inspection): Annahmeprüfung an einem zugelieferten Produkt durch den Abnehmer. | ||||||||
Die Empirie (griechisch embiría - die Erfahrung) stellt im wissenschaftlichen Sinne eine auf methodischem Weg (Induktion, Analogie, Beobachtung und Versuche) gewonnene Erfahrung dar. Hier wird z. B. unter empirische Verteilung eine Verteilung verstanden, die beobachtete oder durch Versuche gewonnenen Daten basiert. | ||||||||
Endprüfung (final inspection): Letzte der Qualitätsprüfungen vor Übergabe der Einheit (Lot, Charge) an den Abnehmer. | ||||||||
Entscheidungsbaum oder Regressionsbaum siehe hier! | ||||||||
Ergebnisabweichung (error of result): Unterschied zwischen einem Merkmalswert und dem Bezugswert, wobei dieser je nach Festlegung oder Vereinbarung der wahre, der richtige oder der Erwartungswert sein kann. (Siehe Genauigkeit und Wahrer Wert) | ||||||||
Ergebnisraum: (Stichprobenraum, Wertebereich eines Merkmals) Ein Ergebnisraum stellt die Anzahl möglicher Zufallsergebnisse dar (siehe auch Merkmal und Zufallsvariable). Ereignisse ET = {1, 2, 3} und einelementige Teilmengen werden als Elementarereignis, wie z. B. Elementarereignis EE = {1} bezeichnet. | ||||||||
Ergebnisunsicherheit (Messunsicherheit): Geschätzter Betrag zur Kennzeichnung eines Wertebereichs, innerhalb dessen der Bezugswert liegt (siehe Vertrauensbereich für den Mittelwert und Wahrscheinlichkeit). | ||||||||
Erhebungsarten siehe Primär- und Sekundärstatistik | ||||||||
Ermittlungsergebnis (result of determination): Durch die Anwendung eines Ermittlungsverfahrens (Prüfmethode) festgestellter Merkmalswert (Merkmalsergebnis). | ||||||||
Erstprüfung: Erste in einer Folge von vorgesehenen oder zugelassenen Qualitätsprüfungen. | ||||||||
Stellt praktisch den Mittelwert der Merkmalergebnisse, die durch “unablässiges” Wiederholen gewonnen wurden, dar. | ||||||||
Suche nach Strukturen und Besonderheiten in den Daten (siehe auch deskriptive und induktive Statistik). | ||||||||
Bei einem Extremwert handelt es sich um auffällig hohe oder kleine Beobachtungen (Messwert...) einer Stichprobe. Hier stellt sich die Frage, ob derartige Beobachtungen als Ausreisser aus der Stichprobe gestrichen werden können. Diese Frage kann mit einem Ausreissertest beantwortet werden. |
Experiment siehe Primär- und Sekundärstatistik |
Faktorenanalyse siehe Multivariate Analysenmethoden |
Faktorielles Desgin ist ein Begriff aus der Varianzanalyse (ANOVA). |
Fehlerfortpflanzung: Rechnen mit fehlerbehafteten Zahlen, siehe hier...! | |||||
Fehler 1. und 2. Art siehe hier! | |||||
Fertigungsprüfung: Zwischenprüfung an einem in der Fertigung befindlichen materiellem Produkt. | |||||
Fischgräten-Diagramm siehe hier! | |||||
Fishers exakter Test siehe hier! | |||||
FMEA steht für Fehlermöglichkeits- und Einflussanalyse. Mehr zum Thema finden Sie hier! | |||||
Maße, die die Abweichung einer Verteilung von der Normalverteilung charakterisieren, wie z. B. Schiefe- und Wölbungsmaße (Momentkoeffizienten). | |||||
Fragebogenkonstruktion, Hinweise zur -: Die folgenden Hinweise sollen Sie bei der Konstruktion eines Fragebogens zur Datenerhebung unterstützen:
Diese Hinweise sind sicher nicht umfassend, sie sollen Anregungen sein! | |||||
|
Auch ist es egal, welche Zahl als 2. Zahl eingetragen wird. Tragen wir einfach die 4 ein: |
|
Die 3. Zahl kann von uns auch willkürlich gewählt werden, hier die 7: |
|
Und ebenso die 4. Zahl, beispielsweise tragen wir hier eine 3 ein: |
|
Und nun kommen wir zur letzten Zahl! Hier haben wir keine Wahlfreiheit mehr! Um die Summe 25 und folglich einen Mittelwert 5 zu erhalten, müssen wir als letzte Zahl 5 eintragen: |
|
Für die Zahlen 1 bis 4 haben wir völlige Wahlfreiheit aber durch die Vorgabe des Mittelwerts 5 in diesem Beispiel, haben wir keine Wahlfreiheit für die 5. Ziffer mehr. In diesem Beispiel haben wir also nur 4 Freiheitsgerade! |
Funktionen, mathematisch betrachtet. |
Genauigkeit (accuracy): Die Genauigkeit ist die Bezeichnung für das Ausmaß der Annäherung von Merkmals- ergebnissen an den Bezugswert, wobei dieser je nach Festlegung oder Vereinbarung der richtige oder ein festgelegter Wert sein kann. Die Genauigkeit ist der Oberbegriff für Präzision und Richtigkeit. |
Gesamtabweichung (total deviation, total error): Ist die Differenz von Sollwert und Istwert und setzt sich zusammen aus systematischer und zufälliger Abweichung. | |||
Gini-Koeffizient als Abweichungsmaß in der Lorenzkurve | |||
GLM (Generalisierte Lineare Modelle): GLM ist eine Analyse-Methode aus dem Bereich der Regressionsanalyse. Besonders ist hierbei, dass die abhängige Variable Y (Zielgröße) einen diskreten Charakter, wie z. B. ja = 1 oder nein = 0, hat (siehe auch Skalen). Ein Anwendungsbespiel dieser Methode finden Sie hier! |
Grenzbetrag (upper limit amount): Betrag für Mindestwert und Höchswert, die bis auf das Vorzeichen übereinstimmen. Grenzabweichung (limiting deviation): Untere Grenzabweichung oder obere Grenzabweichung. Untere Grenzabweichung (lower limiting deviation): Mindestwert minus Bezugswert, wobei der Bezugswert der Nennwert oder Sollwert ist. Obere Grenzabweichung (upper limiting deviation): Höchstwert minus Bezugswert. |
Die Grundgesamtheit ist die Gesamtheit aller Merkmalsträger, oder anders ausgdrückt, ist die Menge aller statistischen Einheiten (Objekte, Elemente), über die
eine Aussage getroffen werden soll.
Wird eine Teilmenge der Grundgesamtheit betrachtet, also darauf beschränkt, wird von einer Teilgesamtheit (Teilpopulation) gesprochen. Nehmen wir als Beispiel eine Befragung zum nächsten Bundeskanzler als Wahlergebnis der Wahl vom 27. September 2009. Die Befragung wird im gesamten Bundesgebiet (räumlich) in der 4. Wochen vor dem Wahltermin für den Zeitraum von einem Tag an 1008 zufällig ausgewählten Bundesbürger (sachlich, Stichprobe = Teilerhebung) durchgeführt. Das Ergebnis der Umfrage soll eine Aussage (Wahrscheinlichkeitsaussage)
sein, wer nächster Bundeskanzler oder natürlich Bundeskanzlerin wird. | ||
H-Test von Kruskal und Wallis siehe hier! |
Häufigkeit, kumuliert (Summenhäufigkeit) siehe hier! |
Hauptkomponentenanalyse, methodisch und mit R finden siehe hier! | ||
Über ein Histogramm lassen sich Häufigkeitsverteilungen grafisch darstellen. Wie ein Histogramm konstruiert wird, sehen Sie hier! | ||
Homoskedastizität (Varianzhomogenität) / Heteroskedastizität spielt insbesondere im lineare Regressionsmodell eine Rolle. Im linearen Modell y = a + bx + e wird davon ausgegangen, dass die Varianz der Residuen e eine konstante Größe und unabhängig von der Ausprägung (dem Wert) der unabhängigen Variable x ist. |
|
| ||||||||||||||||||||
Ein Test auf Heteroskedastizität ist z. B. der Breusch-Pagan-Test (bptest() in R). |
Hypothese, Null- und Alternativ-: Eine ausführlichere Beschreibung des Themas finden Sie hier oder hier als Video ! Durch ein statistisches Testverfahren soll z. B. geprüft werden, ob die Länge der produzierten Schrauben einer laufenden Produktion dem Sollwert = 50 mm entsprechen oder ob beispielsweise zwei Stichprobenmittelwerte innerhalb einer zufälligen Schwankung gleich sind (der gleichen Grundgesamtheit entstammen). Dazu werden Hypothesen formuliert: Die Nullhypothese H0 bedeutet, dass nichts geschieht (einfach ausgedrückt) und die Alternativhypothese H1, dass ein bestimmtes oder extremes Ereignis eingetreten ist. Wichtig ist, dass die Nullhypothese H0 nicht durch Tests bewiesen wird, sondern dass aufgrund der Beobachtungen und Test gezeigt wird, dass die Nullhypothese H0 hinreichend unwahrscheinlich ist! Dann wird zugunsten der Alternativhypothese H1 die Nullhypothese H0 verworfen. Was bedeutet das für obige Beispiele? Zeigt der statistische Test, dass der Sollwert von 50 mm Schraubenlänge innerhalb der normalen statistischen Varianz erreicht wird, ist die Wahrscheinlichkeit hoch, dass die Nullhypothese H0
zutrifft. Zeigt der Test aufgrund der Beobachtungen (deutliche Abweichung der Schraubenlänge von 50 mm) hingegen, dass die Nullhypothese H0 hinreichend unwahrscheinlich ist, muss sie zu Gunsten der Alternativhypothese H1 zurückgewiesen werden. Für Hypothesentests werden zur Entscheidung die entsprechenden tabellierten Verteilungen herangezogen oder durch Statistikprogramme wie z. B. R, p-Werte zur Wahrscheinlichkeitsabschätzung berechnet. Ein Fehler 1. Art tritt nun dann auf, wenn H0 verworfen wird, obwohl H0 wahr ist. Und der Fehler 2. Art tritt dann ein, wenn H0 beibehalten wird, obwohl H1 wahr ist. |
Induktion, Bewies durch vollständige -: Bei der vollständigen Induktion handelt es sich um eine mathematische Beweismethode, nach der eine Aussage A für alle natürlichen Zahlen N bewiesen wird: Wenn aus der Annahme, A(n) sei für ein beliebiges n wahr, folgt, dass A(n + 1)wahr ist, und A(1) ebenso eine wahre Aussage ist, gilt Der Beweis besteht immer aus folgenden Schritten:
|
Versuch durch Einbindung der Stochastik über die erhobenen/ermittelten Daten hinaus allgemeine Schlußfolgerungen für umfassendere Grundgesamtheiten zu ziehen (schließende Statistik, siehe auch deskriptive und explorative Statistik). |
Injektivität, siehe hier! |
Interquartilbereich (interquartilrange, IQR): Der Interquartilbereich kann als Kennzahl für die Verteilung dienen, d. h., die Größe des Bereichs gibt Auskunft, wie weit die Verteilung auseinander gezogen ist. | ||||
Der Interquartilbereich ist, da links von Q1 und rechts von Q3 die Werte nicht berücksichtigt werden, gegen Extremwerte (Ausreißer) stabil. Als Ausreißer-Kandidaten können Werte vermutet werden, die folgende Grenzen überschreiten: | ||||
Unterer Grenzwert = Q1 - 1,5 dQ Oberer Grenzwert = Q3 + 1,5 dQ | ||||
(EN) ISO 9001:2000 ff, QM-System (EN) ISO 19011, Leitfaden für das Auditieren von Qualitäts- und /oder Umweltmanagementsystemen | ||||
Istwert: Momentanes Merkmalsergebnis, welches sich durch systematische und /oder zufällige Abweichungen vom wahren/richtigen Wert unterscheidet. | ||||
Ein Intervall stellt eine zusammenhängende Teilmenge einer geordneten Menge dar. Das bedeutet, wenn 2 Objekte in der Teilmenge enthalten sind, sind auch die dazwischen liegenden Objekte in dieser Teilmenge enthalten.
Um Verwechselungen mit dem Dezimalkomma zu vermeiden, werden oft folgende Schreibweisen genutzt: [1, 10] = [1; 10] = [1 | 10] Die oben gezeigten Beispiel-Intervalle sind endlich und die größte untere Schranke heißt Infimum und die kleinste obere Schranke Supremum. Neben den endlichen gibt es natürlich auch unendliche Intervalle, z. B.: [0, |
Ishikawa-Diagramm siehe hier! |
Julia, Die Programmiersprache - |
Junktoren, siehe hier! |
Justieren bedeutet, ein Messgerät so einzustellen oder abzugleichen, dass die Messabweichungen möglichst klein werden oder dass die Beträge der Messabweichungen die Fehlergrenze nicht überschreiten. (DIN 1319 Teil 1) |
Das Kalibrieren eines Systems ist die Ermittlung und Festlegung eines funktionalen Zusammenhangs zwischen einer zähl- bzw. messbaren Größe und einer bestimmenden Konzentration (Objekteigenschaft) aus Daten, die im allgemeinen mit zufälligen Abweichungen behaftet sind. (DIN 1319 Teil 1) |
Kardinalzahlen sind Mengen, die als Repräsentanten von Mengen einer bestimmten Größe dienen (Anzahl, siehe auch Skalen). |
Kartesische Produktmenge, siehe hier! | |||||
Klassierung (Kategorisierung) von Merkmalsausprägungen siehe hier! | |||||
Kommunalitätsproblem als Aspekt der Faktorenanalyse siehe hier! | |||||
Kommutativgesetz: (siehe auch Assoziativgesetz) a+b = b+ a a*b = b* a | |||||
KMO-Kriterium, Kaiser-Meyer-Olkin-Kriterium Eignungsprüfverfahren in der Faktorenanalyse, siehe hier! | |||||
Kolmogorov-Smirnov-Test (Kolgoroff-Smirnoff-Test) als Anpassungstest zur Prüfung auf Normalverteilung siehe hier! | |||||
Konfidenzbereich /-intervall (confidence interval): siehe Vertrauensbereich | |||||
Kontingenz- oder Kreuztabelle und Kontigenzanalyse, oder Übersicht der Multivariaten Analysenmethoden | |||||
Kontingenzkoeffizienten K*, Kontigenzanalyse, Stärke des Zusammenhangs... |
Korrelation (correlation): Allgemeine Bezeichung für den stochastischen Zusammenhang zwischen zwei oder mehreren Zufallsgrößen. Im engeren Sinn wird mit “Korrelation” der lineare stochastischen Zusammenhang bezeichnet. Sind die Beobachtungen vom metrischen Skalentyp, wird der Korrelationskoeffizient nach Pearson geschätzt und sind sie mindestens vom ordinalen Skalentyp, nach Spearman (Rangkorrelationskoeffizient). Über den t-Test für den Korrelationskoeffizienten, können Sie die Güte des vermuteten statistischen Zusammenhanges zwischen den Merkmalen prüfen. Weiters dazu hier! |
Korrelationsmatrix, Inverse -, siehe hier! |
Korrespondenzanalyse siehe Multivariate Analysenmethoden | ||||
Kreisprozess: Um auf Fragestellungen Antworten (Resultate) zu finden, hilft der statistische Kreisprozess weiter. Auf Basis der Fragestellung werden die geplanten Daten erhoben, Annahmen über das Modell gemacht, die Daten analysiert und interpretiert. Zeigen Fragestellung und Resultate keinen “inneren” Zusammenhang (Modell / Interpretation) müssen Anpassungen vorgenommen werden, bis dass Modell die Realität befriedigend abbildet. | ||||
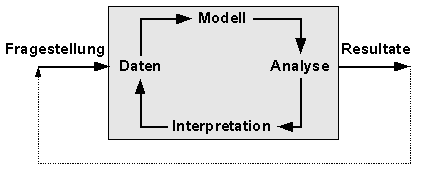 | ||||
Kruskal und Wallis-Test (oder H-Test) siehe hier! |
Laplace-Wahrscheinlichkeit siehe hier! |
Zum Thema Lebensdaueruntersuchung (Zuverlässigkeits-) siehe Weibullverteilung! |
Likert-Skala (nach Renisis Likert), siehe hier! |
Logistische Regression , siehe hier! | |||
Logische Verknüpfung, siehe hier! | |||
Logit: Begiff aus der logistischen Regression, siehe hier! |
Maße für die mittlere Lage einer Verteilung, wie z. B. der Mittelwert. |
Lorenzkurve als garphische Darstellung der relativen Merkmalkonzentration. |
Los: Begriffe zur Probenahme |
Matrix, mathematisch - |
Matrix: (chemisch -) Die Matrix ist die Gesamtheit der Bestandteile eines Materials und ihrer chemischen und physikalischen Eigenschaften und deren gegenseitigen Beeinflussungen. |
Mengenlehre: Grundbegriffe der Mengenlehre siehe hier! | |||||||
Eigenschaft zum Erkennen oder zum Unterscheiden von Einheiten (Charge, Los,
Untersuchung einer Grundgesamtheit). | |||||||
| |||||||
Qualitativ: Attributives oder beschreibendes Merkmal | |||||||
Gruppierte oder klassierte Merkmale sind zusammengefasste Merkmalsausprägungen. Werden stetige Merkmale gruppiert, können sie als diskret angesehen werden. Ob ein Merkmal stetig oder diskret ist, kann vom Modell und der Messmethode abhängen. Bei der Wahl der Messmethode, spielt die angemessene Beschreibung der Realität (Modell) und die mathematisch statistische Berechenbarkeit eine Rolle. | |||||||
Merkmalswert: (characteristic value, auch Prüfergebnis, siehe auch Qualität, Wertdefinitionen und Skalen) Der Erscheinungsform des Merkmals zugeordneter Wert. Wertebereich eines Merkmals: Menge aller Merkmalswerte, die das betrachtete Merkmal annehmen kann. Für (Untersuchungs-) Merkmale werde oft große lateinische Buchstaben wie z. B. X und für die Ausprägung, also den Wert des Merkmals, kleine lateinische Buchstaben wie in diesem Beispiel x verwendet: X = Alter des Befragten Die Ausprägung x ist die Realisierung des Merkmals X. | |||||||
Messprobe: (auch Analysenprobe) Eine Messprobe ist diejenige Probe, deren Gehalt an einem zu bestimmenden Stoff unmittelbar gemessen werden kann. Sie wird aus der Laboratoriumsprobe durch Zusätze von Reagenzien, oder allgem. durch Bearbeitung, erhalten. | |||||||
Randomisierte Studien sind die bestmöglichen Voraussetzungen zur Beurteilung eines Therapieerfolges. Systematische Zusammenfassungen dieser randomisierten Studien sind ein wesentlicher Schritt im Erkenntnisgewinn und derartige Zusammenfassungen werden als Übersichtsarbeit oder Review bezeichnet. Übersichtsarbeiten sind dadurch gekennzeichnet, dass in systematischer Weise nach Studien zu einer bestimmten Fragestellung gesucht wird.
Diese Studien sollen unabhängig von ihrem Ergebnis in die Bewertung (der Übersichtsarbeit) einfließen. (Diese Forderung ist schwierig einzuhalten, da Studien, die einen negativen Therapieerfolg als Ergebnis zeigen, wenig Chancen auf Veröffentlichung haben!) |
Die 8D-Methode beschreibt einen teamorientierten Problemlösungsprozess und legt eine Schrittfolge fest, die durchlaufen werden soll, wenn ein Problem mit unbekannter Ursache offensichtlich wird. Mehr hier....! | ||
Mittelwert (mean), arithmetischen ... | ||
Mittel, geometrisch: Das geometrische Mittel |
Mittel, gewogen: Der gewogene arithmetische Mittelwert wird im Bereich der Datenzusammenfassung dargestellt. |
Mittel, harmonisch: Das harmonische Mittel | |||
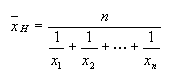 | |||
Über das harmonische Mittel lässt sich dann die mittlere Geschwindigkeit eines Fahrzeugs ausdrücken, das von A nach B fährt und für verschiedene Streckenabschnitte bestimmte Zeiten benötigt. Folgendes Beispiel zeigt die Berechnung des harmonischen Mittelwertes: |
|
|
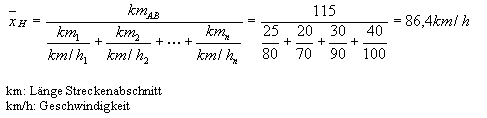 |
Die Durchschnittsgeschwindigkeit für die Strecke von Punkt A nach Punkt B beträgt 86,4 km/h. |
Mittelwert, Schwerpunkteigenschaft: Für den arithmetischen Mittelwert | |||
D. h., die Summe der Abweichung zwischen xi und |
Mittelwert-t-Test: Mit diesem Test wird die Frage beantwortet, ob 2 Mittelwerte aus Datenreihen vom Umfang n1 und n2 unterschiedlich sind. D. h., entstammen beide Mittelwerte einer Grundgesamtheit oder nicht? Mehr dazu hier...! |
Mittlere absolute Abweichung (MAD, Mean absolute Deviation): Als Gütemerkmal einer Prognose kann die mittlere quadratische Abweichung MSE als Kostenfunktion C
über
geschätzt werden. Bei der Beurteil des MAD’s ist die Verteilung, die Auswirkung von Extremwerten (auch wenn sie geringer ist als für den MSE-Schätzer) und eine mögliche Autokorrelation der in das Modell einfließenden Merkmale zu betrachten. |
Mittlere quadratische Abweichung (MSE, Mean Squared Error): Als Gütemerkmal einer Prognose kann die mittlere quadratische Abweichung MSE als Kostenfunktion C
über
geschätzt werden. Bei der Beurteil des MSE’s ist die Verteilung, die Auswirkung von Extremwerten und eine mögliche Autokorrelation der in das Modell einfließenden Merkmale zu betrachten. |
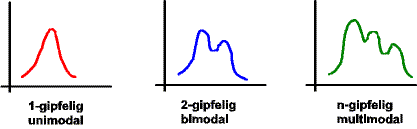
Der Modus xmod ist ein Lagemaß und zeigt die Ausprägung (Merkmalswert, Klasse) mit der größten Häufigkeit. Er ist eindeutig, wenn die Häufigkeitsverteilung ein eindeutiges Maximum besitzt. In einem Histogramm (Stab- oder Säulendiagramm) ist er die höchste Säule, die Klasse mit der höchsten Häufigkeit. Besitzt die Ausprägung mindestens ordinales Skalenniveau, kann die Häufigkeitsverteilung auch mehrere voneinander getrennte Maxima besitzen. |
Moment siehe Potenzmomente | ||
Multidimensionale Skalierung siehe hier oder Multivariate Analysenmethoden | ||
Multiple lineare Regression siehe hier...! | ||
n-dimensionale Daten, d. h. Daten, die aus Beobachtungen von n Merkmale bestehen (siehe auch univariate Daten). Eine Übersicht über Multivariate Analysemethoden wird hier gegeben. |
Nachweisgrenze : (auch Bestimmungsgrenze) Die Nachweisgrenze stellt den unteren Bereich des Arbeitsbereiches einer Prüfmethode dar (siehe auch Blindwert). |
xi >= 3 sx |
Wenn das Prüfergebnis (Merkmalswert, xi) wie im obigen Beispiel, 3 mal größer ist als die Standardabweichung sx, gilt das Ergebnis als gesichert nachgewiesen. |
|
| ||||||||||||||||||||||||||||
Neuronale Netze siehe Multivariate Analysenmethoden |
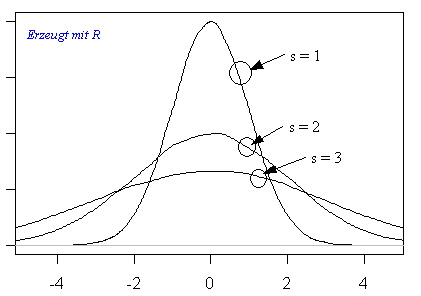
Eine wichtige Verteilung in der Statistik ist die Normalverteilung. Und oft geht es um die Frage, ob die beobachteten Werte (z. B. Messwerte) einer Normalverteilung folgen oder nicht. Die Normalverteilung ist eine Dichtekurve, die symmetrisch, unimodal und glockenförmig ist. Diese Art von Dichtkurven, werden durch folgende Dichtfunktion beschrieben:
Folgende Grafik zeigt die Normalverteilung in Abhängigkeit von der Standardabweichung s:
Da in obiger Dichtefunktion Mittelwert und Standardabweichung beliebige Werte annehmen
können, existieren beliebig viele unterschiedliche Normalverteilungen. Obige Abbildung ist eine Beispiel für konstantem Mittelwert und 3 verschiedene Standardabweichungen.
Über diese Standardisierung lassen sich dann die wichtigen Quantile berechnen. Siehe auch Verteilungen! | |||||||
Normalverteilung siehe Student-Verteilung | |||||||
Normalverteilung, Abweichung von Abweichungen von der Normalverteilung lassen sich, neben der unter obigen Link beschriebenen Methoden, sehr schnell visuell abschätzen. Das kann mittels Histogramm oder über einen Quantil-Quantil-Plot (QQ-Plot) geschehen: | |||||||
 | |||||||
Liegen wie im obigen Beispiel-Plot die Beobachtungen (z. B. Messwerte) auf oder ziemlich nahe an der Hilfslinie, kann von einer sehr guten Näherung an die Normalverteilung ausgegangen werden. |
Normen: EN ISO 9000:2000 ff (Systemnorm) |
Normierung, siehe Z-Normierung |
Odds Ratio siehe hier! |
Ordinalzahl ist eine Menge, die den Ordnungstyp einer wohlgeordneten Menge repräsentiert (Ordnungszahl, siehe auch Skalen). |
Ordinate: Bezeichnung für die “vertikale” Koordinate des kartesischen Koordinatensystems (y-Achse). |
Ordnungszeichen (Zahlen-), siehe hier! |
Panelerhebung: Eine Panelerhebung ist eine Mehrfacherhebung, die sich auf eine repräsentative Teilauswahl (Panel) bezieht. Die Datenerhebung wird immer zum selben Untersuchungsgegenstand gemacht. Das heißt, es wird eine Mehrfacherhebung zu den selben Merkmalen zu verschiedenen Zeitpunkten mit der gleichen Teilauswahl (d. h. die selben Teilnehmer) durchgeführt. Der Zweck der Panelerhebung ist, durch die periodische Erhebungen zeitliche Veränderungen sichtbar zu machen. Diese Methode stellt eine Zeitreihenuntersuchung auf Individualebene dar. Dadurch werden Längsschnittdaten erhalten, die als Grundlage für Prognosen zur Marktbeurteilung herangezogen werden können (Handel- / Verbraucherpanels). |
|
|
Population: siehe Grundgesamtheit | |||
Potenzmomente beschreiben die Abweichung von der Normalverteilung. | |||
Ist die Bezeichnung für das Ausmaß der gegenseitigen Annäherung voneinander unabhängiger Merkmalsergebnisse bei mehrfacher Anwendung einer festgelegten Prüfmethode. Die Präzision beschreibt den zufälligen Fehler (zufällige Abweichung, Varianz). Es wird unterschieden zwischen Wiederholpräzision und der Vergleichspräzision. | |||
Primär- und Sekundärstatistik: Wurden die Daten für eine Untersuchung auf Basis von Erhebungen gesammelt, wird von Primärstatistiken (Field Research) gesprochen. Dabei werden folgende Beobachtungsarten unterschieden:
Von Sekundärstatistiken wird gesprochen, wenn diese Daten nicht zum Zwecke einer statistischen Untersuchung erhoben wurden, sondern z. B. in der behördlichen Verwaltung oder durch eine wirtschaftliche Tätigkeit angefallen sind. Vertraute Beispiele dürften die Kfz-Zulassungszahlen bezogen auf die Automarken oder im Rahmen einer wirtschaftlichen Tätigkeit, die Rohölpreisentwicklung. Die Daten zur Untersuchung sind also schon vorhanden. |
Primzahl: Eine Primzahl p ist eine natürliche Zahl (p > 1), die nur durch sich selbst und durch Eins ohne Rest teilbar ist. Z. B. p = 2,3,5,7,11,13,17,19,... |
Grafische Darstellung der Begriffe zur Probenahme Los (lot): Menge eines Produkts, das unter Bedingungen entstanden ist, die als einheitlich angesehen werden können. Bei dem Produkt kann es sich beispielsweise um Rohmaterial, um Halbzeug, oder um ein Endprodukt handeln. Unter welchen Umständen die Bedingungen als einheitlich angesehen werden können, lässt sich nicht allgemein angeben. Es kann ein Wechsel des eingesetzten Materials, des Werkzeugs oder eine Unterbrechung des Herstellvorgangs zu anderen Bedingungen führen. Für den Begriff Los wird in bestimmten Branchen auch synonym “ Charge” oder “Partie” verwendet. Losumfang (lot size): Anzahl der Einheiten im Los (z. B. 10000 Schrauben oder 5000kg einer chemischen Substanz). Prüflos (inspection lot): Los, das als zu beutreilende Gesamtheit einer Qualitätsprüfung unterzogen wird. Probe, Stichprobe (sample): Eine oder mehrere Einheiten, die aus der Grundgesamtheit (z. B. einer Charge oder Lieferung) oder aus Teilgesamtheiten entnommen werden. Stichprobenumfang (sample size): Anzahl der Einheiten in der Stichprobe. Einzelprobe (increment): Durch einmalige Entnahme aus einem Massengut entnommene Probe. Sammelprobe (bulk sample, gross sample): Probe, die durch Zusammenfassung von Einzelproben oder Teilproben ensteht. Teilprobe (divided sample): Probe, die durch ein Probeteilungsverfahren aus Einzel- oder Sammelproben gewonnen wird. Laboratoriumsprobe (laboratory sample): Probe, die als Ausgangsmaterial für die Untersuchung im Laboratorium dient (siehe Messprobe). Probennahme, Stichprobennahme (sampling): Entnahme einer Probe nach festgelegten Verfahren. | |||
Produktmenge, kartesische - | |||
Proximität: Proximität ist ein Begriff aus der Distanzanalyse (z. B. Multidimensionale Skalierung, Clusteranalyse) und beschreibt Ähnlichkeits- bzw. Unähnlichkeitskoeffizienten. |
Was ist ein fähiger Prozess und wie wird dieser beschrieben? Siehe hier...! | ||
Prüfmethode, -verfahren, -anweisung (inspection instruction): Beschreibt die Durchführung zur Ermittlung der Merkmalswerte für Prüfmerkmale. Liegt eine Prüfspezifikation vor, ist sie die Grundlage für die Prüfmethode. | ||
Prüfspezifikation (inspection specification): Festlegung der Prüfmerkmale für die Qualitätsprüfung und gegebenenfalls der vorgegebenen Merkmalswerte sowie erforderlichenfalls der Prüfverfahren (-methode). | ||
Hypothesenentscheidung auf Basis des p-values in der Anwendung von Statistikprogrammen wie z. B. R siehe hier...! |
QQ-Plot siehe hier! |
Qualität (quality): Ist die Gesamheit der Merkmale und Merkmalswerte, bzw. deren Ausprägung, eines Objektes (z. B. Produkt, Dienstleistung) bezüglich seiner Eignung, festgelegte und vorausgesetzte Erfordernisse zu erfüllen (nach DIN 58936 Teil 1) |
Qualitätsmerkmal (quality characteristic): Ist ein Merkmal, das die Qualität eines Objektes beschreibt. Es ist damit ein Element der Gesamtheit aller die Qualität eines Objektes charakterisierender Kennzeichen und Eigenschaften (nach DIN 58936 Teil 1). |
Bescheinigung über das Ergebnis einer Qualitätsprüfung, das gegenüber dem Abnehmer oder Auftraggeber als Nachweis über die Qualität eines Produkts dient. Ein Zertifikat enthält Angaben über: |
|
Qualitätssicherung (quality assurance): Ist die Gesamtheit der Tätigkeiten des Qualitätsmanagements, der Qualitätsplanung, der Qualitätslenkung und der Qualitätsprüfung. Qualitätssicherung ist als integrierter Prozess in der Wertschöpfungskette zu verstehen. Qualitätsmanagement ist der Aspekt des Gesamtmanagements, der die Qualitätspolitik festlegt und zur Ausführung bringt (siehe QM-System). Qualitätsplanung bedeutet auswählen, klassifizieren und gewichten der Qualitätsmerkmale und konkretisieren der Qualitätsanforderung unter Berücksichtigung von Anspruch und Realisierungsmöglichkeiten. Qualitätslenkung bedeutet, Überwachung der Qualitätsmerkmale im Hinblick auf die gegebenen Forderungen sowie gegebenenfalls Korrekturmaßnahmen. Qualitätsprüfung bedeutet festzustellen, inwieweit das Objekt die Qualitätsforderung erfüllt. (Nach DIN 55350 Teil 11 und DIN 58936 Teil 1) |
Qualitätssicherungssystem (quality control system): Ein Qualitätssicherungssystem beschreibt die festgelegte Organisation zur Durchführung der Qualitätssicherung. |
Ein Quantil (Unterteilung der Grundgesamtheit) oder Quartil (Quartile teilen die Grundgesamtheit in 4 gleich große Teile) ist ein Lokalisationsmaß einer stetigen Verteilung, bei dem die Wahrscheinlichkeit p für einen Wert <= p oder => 1-p ist. Der Median ist das 50%-Quantil, d. h., hier sind 50% der Werte <= dem Median und 50% der Werte => dem Median. x0,75 - x0.25 = Quartilabstand
Der Quartilabstand gibt an, wie die mittleren 50% der Beobachtungen streuen (siehe auch Boxplot). |
|
Ist die Verteilung annähernd symmetrisch zum Median, sind Q1 und Q3 gleich weit vom Median entfernt. Siehe auch QQ-Plot! |
Quantoren ist ein Begriff aus der Logik und ermöglichen das kurze Formulieren von Existenz- und Allaussagen:
Beispiel: Es gibt eine Zahl, die Teiler von 12 ist: Siehe auch Junktoren, Wahrheitswerttabelle und Relationen. |
Radiant rad, Beziehung Radiant (Bogemaß) und Grad. |
Rangkorrelationskoeffizient, siehe hier! |
Ratingverfahren (Likert-Skala (nach Renisis Likert)): Verfahen zur Erhebung von Ähnlichkeitsurteilen, siehe MDS (Multidimensionale Skalierung). |
Referenzmaterial (reference material): Ein Referenzmaterial ist eine Substanz, deren Eigenschaft / Eigenschaften so genau festgelegt oder bekannt sind, dass sie zur Kalibrierung von Messgeräten und Kontrolle der Prüfmethode verwendet werden kann. | ||||||||||
Regelkarte: Qualitätsregelkarten sind Werkzeuge zur statistischen Prozesskontrolle, mehr dazu hier...! | ||||||||||
Regression, logistische siehe Multivariate Analysenmethoden | ||||||||||
Regressionsanalyse siehe Korrelations- und Regressionsanalyse oder Multivariate Analysenmethoden | ||||||||||
Regressionsbaum siehe hier! | ||||||||||
Durch Relationen (relationale Operatoren) werden Beziehungen zwischen Zahlen dargestellt: | ||||||||||
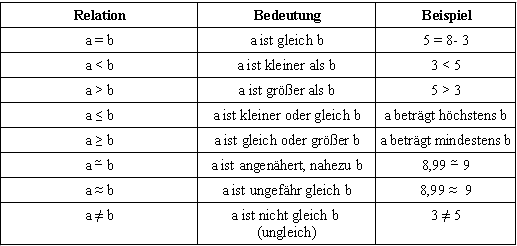 | ||||||||||
Relatives Risiko siehe hier! |
Reliabilität bedeutet, dass die Beobachtungen (Daten) zuverlässig ermittelt werden. Zuverlässig bedeutet, die Daten mit einer möglichst hohen Güte und Genauigkeit zu bestimmen. D. h, es müssen Bedingungen vorliegen oder geschaffen werden, die Beobachtungsdaten mit einem möglichst kleinen Fehler bestimmt werden können. Validität und Reliabilität stehen in einer engen Beziehung. Wird eines von beiden vernachlässigt, können die gesamten Beobachtungen wertlos sein. | |||||
Als Residuen e wird die Abweichnung zwischen der Zielgröße y (Vorgabe einer Kalibrierung) und dem berechneten Wert der Zeilgröße yo = a + bx, bezeichnet: | |||||
ei = yi - yoi | |||||
Mit ihrer Hilfe können Aussagen über die Korrektheit des linearen Modells gemacht werden (siehe Korrelation). Ist das Modell korrekt, müssen sich die Werte von ei im gesamten Bereich von yoi ohne erkennbare Struktur um 0 sammeln. | |||||
Richtiger Wert (conventional true value): Wert für Vergleichszwecke, dessen Abweichung vom wahren Wert für den Vergleichszweck als vernachlässigbar betrachtet wird. | |||||
Richtigkeit (trueness, accuracy of the mean): Die Richtigkeit ist eine Bezeichnung für das Ausmaß der Annäherung des Mittelwertes der Merkmalergebnisse an den Bezugswert, wobei dieser je nach Festlegung oder Vereinbarung der richtige oder ein festgelegter Wert sein kann. Die Richtigkeit beschreibt den systematischen Fehler (systematische Abweichung). |
RPZ, Risikoprioritätszahl: Maßzahl einer FMEA, Fehlermöglichkeits- und Einflussanlayse (Failure Mode and Effects Analysis), mehr dazu hier! |
Gewünschte Eigenschaften einer Schätzfunktion:
|
Schiefe: Siehe Abweichung von der Normalverteilung. | |||||
Schlussregeln (mathematische -): Eine Schlussregel ist eine Aussagelogik wie “Wenn a eine hinreichende Bedingung für b ist und a wahr ist, dann ist auch b wahr!” | |||||
Schwerpunkteigenschaft des Mittelwerts | |||||
Mit dem Shapiro-Wilk-Test wird die Hypothese geprüft, ob die Beobachtungen X normalverteilt sind. Dazu wird die Verteilung des Quotienten aus zwei Schätzungen der Varianz s2 betrachtet: das Quadrat einer kleinsten Fehlerquadratschätzung für die Steigung der Regressionsgraden im QQ-Plot und die Stichprobenvarianz. Liegt Normalverteilung vor, sollten beide Schätzung nahe zusammenliegen und der Quotient W sollte 1 oder nahe bei 1 liegen. |
|
|
Der Quotient W liegt nahe bei 1 und der p-Wert (p-value) als Wahrscheinlichkeitsaussage zum Zutreffen der Hypothese ist genügend groß. Weicht W deutlich von 1 ab und geht der p-Wert deutlich in Richtung 0 (z. B. < 0,05) ist von einer Abweichung von der Normalverteilung auszugehen. |
Signifikanzniveau: siehe Wahrscheinlichkeit | ||||||||||||||||||
Six Sigma, ein methodisches Vorgehen zur Prozessverbesserung, siehe hier...! |
||||||||||||||||||
 | ||||||||||||||||||
Ist die Differenz aus dem größten und dem kleinsten Merkmalswert: R = xmax - xmin | ||||||||||||||||||
Spearman, Rangkorrelationskoeffizient nach ... | ||||||||||||||||||
Splines, Regressionanalyse über die flexible Modellierung mit ... | ||||||||||||||||||
Standardabweichung: siehe Statistik-Basis | ||||||||||||||||||
Statistik, Die drei Bereiche der -: Einen kleinen Überblick über die drei Statistikbereiche soll folgende Grafik geben: | ||||||||||||||||||
 | ||||||||||||||||||
Statistische Prozessüberwachung (statistical process control, SPC):
Sie ist der Teil der Qualitätskontrolle / -lenkung, bei der statistische Verfahren zur Planung und Aus-/Bewertung eingesetzt werden (nach DIN 58936 Teil1, siehe auch Prozessfähigkeit und Regelkarten!). | ||||||||||||||||||
Sterbetafel: Zur Sterbetafel im Rahmen der Weibullverteilung geht es hier....! | ||||||||||||||||||
Stichprobe: siehe Probennahme | ||||||||||||||||||
Stichprobenraum: siehe Ergebnisraum | ||||||||||||||||||
Strukturgleichungsmodelle siehe Multivariate Analysenmethoden | ||||||||||||||||||
Stochastik: Teilgebiet der Mathematik, das sich mit zufälligen Ereignissen befasst (Wahrscheinlichkeitsrechnung). | ||||||||||||||||||
Student-Verteilung, t-Verteilung (Tabelle der t-Verteilung) | ||||||||||||||||||
Summenformel, Arithmetische - | ||||||||||||||||||
Summenformel, Geometrische - | ||||||||||||||||||
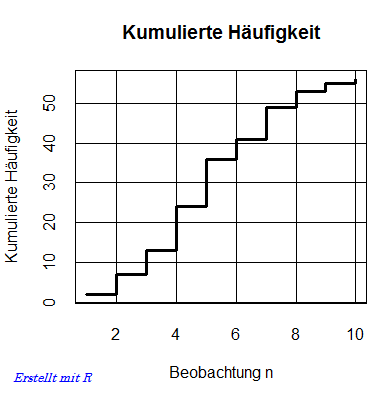
Summenhäufigkeit, kumulierte Häufigkeit: Über ein Histogramm können Sie einen visuellen Eindruck über die Verteilung Ihrer Beobachtungen gewinnen (siehe auch Skalen). Möchten Sie hingegen wissen, wie viele Beobachtungen unterhalb oder einschließlich einer bestimmten Grenze (Klasse) liegen, hilft die kumulierte Häufigkeit weiter. Zur Bildung der kumulierten Häufigkeiten werden die Beobachtungen beginnend mit der kleinsten Ausprägung in aufsteigender Reihenfolge aufaddiert (kumuliert). Die folgende Tabelle zeigt ein Beispiel: |
| |||||||||||||||||||||||||||||||||||||||||||||
Die kumulierte Summe für n = 4 setzte sich zusammen aus der Summe = n1+n2+n3+n4 = 2+5+6+11 = 24. D. h., bis einschließlich n4 liegen 24 Beobachtungen vor! Formaler lässt sich das als Summenhäufigkeits-Funktion ausdrücken: |
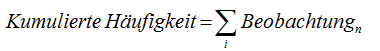 |
|
|
Systematische Abweichung (systematic deviation, systematic error): Siehe Richtigkeit. Systematische Abweichungen weisen bei definierter Vorgehensweise (z. B. gleiche Prüf- methode) gleiches Ausmaß und Vorzeichen auf. Bei quantitativen Merkmalswerten ist die systematische Abweichung, unter Berücksichtigung der vorangemachten Ausage, gleich der Differenz aus Erwartungswert und richtigem bzw. wahrem Wert.
|
Teilerfremd: Zwei natürliche Zahlen sind teilerfremd, wenn es keine natürliche Zahl außer der 1 gibt, die beide Zahlen teilt. Ein Bruch zweier teilerfremder Zahlen kann nicht weiter gekürzt werden. |
Test:
|
Ein Term ist ein sinnvoller Ausdruck, der Zahlen, Variablen, Symbole (auch mathematische Verknüpfungen) enthalten kann: f(x) = a + bx a: konstanter Term Umgangssprachlich: Ein Term ist das, was Bedeutung trägt! | |||
Welchem Prinzip ein statistischer Test folgen sollte, finden Sie hier! | |||
Ein Theorem ist ein allgemeiner Lehrsatz, ein Bestandteil einer wissenschaftlichen Theorie oder Lehrmeinung: “Der erklärende Satz einer Aussage / eines Systems” Theorem = Lehrsatz = Satz Ein Satz muss mit den Axiomen der Theorie und mit den Schlussregeln der Theorie bewiesen werden. |
Toleranz (tolerance): Höchstwert minus Mindestwert und auch obere Grenzabweichung minus untere Grenzabweichung. Toleranzbereich (tolerance zone): Bereich zugelassener Werte zwischen Mindestwert und Höchstwert. |
Trendtest siehe hier! |
... Differenzen siehe hier! ... Sollwerte siehe hier! ... den Korrelationskoeffizient: Über den t-Test zur Prüfung der Korrelationskoeffizienten kann geprüft werden, ob ein statistisch signifikanter Zusammenhang zwischen den Ausprägungen (Realisierungen) xi und yi der Merkmale X und Y besteht. Weiteres finden Sie hier! | ||
Tupel, n-Tupel siehe hier! | ||
t-Verteilung siehe Student-Verteilung |
Unabhängige identische Wiederholung: Näheres finden Sie hier! |
Eindimensionale Daten, d. h. Daten, die aus Beobachtungen eines einzelnen Merkmals bestehen (siehe auch multivariate Daten). |
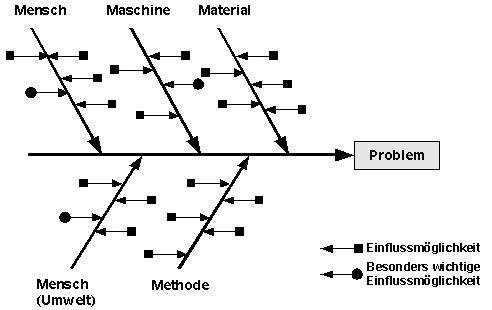
Ursache-Wirkungs-Diagramm: (Fischgräten- oder Ishikawa-Diagramm, K.Ishikawa 1915-1989) Durch ein
Ursache-Wirkungs-Diagramm kann die Suche nach Fehlerursachen in einem Prozessablauf erleichtert werden. Es ist möglich, auf Basis dieses Diagramms auch komplexe Zusammenhänge zu visualisieren und dadurch zu analysieren. Dabei wird wie im folgenden Bild gezeigt, von den Ursachen, z. B. den 5 M`s, auf das Ereignis (Problem) geschlossen:
|
Validität bedeutet einfach ausgedrückt, die Daten zu messen (beobachten), die Gegenstand der Untersuchung sind. Wenn der Beobachter an der Körpergröße des Menschen interessiert ist, soll sie von den Füßen bis einschließlich des Kopfes gemessen und nicht der Bauchumfang bestimmt werden. Validität und Reliabilität stehen in einer engen Beziehung. Wird eines von beiden vernachlässigt, können die gesamten Beobachtungen wertlos sein. |
Eine Variable (lat.: variabilis) wird als Platzhalter oder als eine Veränderliche in einem mathematischen Ausdruck verstanden. Im statistischen Zusammenhang, ist eine Variable der Träger der Ausprägung einer Beobachtung. Soll z. B. in einem bestimmten Kontext die Körpergröße der Bevölkerung ermittelt werden, ist die Beobachtung die Körpergröße in cm, die Variable vielleicht Größe und die Ausprägung für eine Beobachtung (aus der Stichprobe) möglicherweise 182. Derartige Variablen sind direkt beobachtbar, d. h., messbar und werden auch manifeste Variablen genannt. Latente Variablen sind Variablen, die nicht direkt beobachtbar sind, wie z. B. Qualität, Intelligenz, Solidarität, usw.. Sie müssen durch die sogenannte Operationalisierung zunächst messbar
gemacht werden. Die in der Operationalisierung gemachten Annahmen werden als Messmodell bezeichnet. Das Messmodell beschreibt zur indirekten Messung der latenten Variable, wie z. B. dem Intelligenzquotienten, Merkmale, die direkt beobachtet werden können (manifeste Variablen). Diese manifesten Variablen werden auch Indikator-Variablen genannt. Proxy-Variable ist ein Synonym für die latente Variable.
Ein Video zum Thema latente Variable finden Sie hier! |
Varianz: siehe Statistik-Basis |
Varianzanalyse siehe Multivariate Analysenmethoden |
Variationskoeffizient siehe hier! |
Vergleichsbedingungen: Bei der Gewinnung von unabhängigen Merkmalswerte gelten folgende Bedingungen: festgelegte Prüfmethode, identisches Objekt (Material), verschiedene Prüfer (Beobachter), eventuell verschiedener Prüfausstattung (Geräte) und verschiedene Orte (Labors). |
Vergleichspräzision (reproducibility): Die Vergleichspräzision ist die Bezeichnung für das Ausmaß der gegenseitigen Annäherung der Merkmalswerte unter Vergleichsbedingungen. |
Verknüpfungen , logische -, siehe hier! | ||||||
Verteilungen, Gipfeligkeiten von: Folgende Grafik zeigt mögliche Häufigkeitsverteilungen und deren Bezeichnungen: | ||||||
 | ||||||
Verteilung, |
||||||
Verteilung, Binomial- | ||||||
Verteilung, geometrische |
Verteilung, hypergeometrische | ||
Verteilung, Normal-, Student- (t-) | ||
|
Verteilung, Poisson- | ||
Verteilung, Weibull- |
Vertrauensbereich, Konfidenzbereich (confidence interval): Unter Vertrauensbereich wird ein aus Stichprobenwerten berechnetes, d. h. in der Lage und Breite zufälliges Intervall, das den wahren aber unbekannten Parameter mit einer vorgegebenen Wahrscheinlichkeit, der Vertrauenswahrscheinlichkeit, überdeckt (einschließt), verstanden. Die Grenzen des Intervalls werden Vertrauensgrenzen (confidence limits) genannt. Siehe Berechnung Vertrauensbereich für den Mittelwert |
Verzerrung siehe Bias |
Vorzeichenregel siehe hier! |
Wahrer Wert (true value): Tatsächlicher Merkmalswert; ist in der Regel aber nur ein ideeller Wert, weil er sich praktisch nicht ermitteln lässt. Es können i. d. R. zu dessen Ermittlung nicht alle Faktoren, die zur Ergebnisabweichung beitragen, vermieden werden (nach DIN 55350 Teil12). |
Die Wahrscheinlichkeitsverteilung einer Zufallsvariablen gibt an, mit welcher Wahrscheinlichkeit die Werte der Zufallsvariablen angenommen werden. Diese Wahrscheinlichkeitsverteilung wird durch die Verteilungsfunktion eindeutig definiert: |
F(x) = P(X <= x) |
F(x) gibt die Wahrscheinlichkeit an, dass die Zufallsvariable X einen Wert kleiner oder gleich x annimmt. Nimmt die Zufallsvariable x diskrete Werte an, wird von einer Wahrscheinlichkeitsfunktion (probability function, frequency function) gesprochen. Die Verteilungsfunktion wird durch Aufsummieren der Wahrscheinlichkeiten | |||
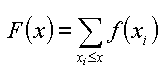 | |||
ermittelt. Für stetige Zufallsvariablen wird die Verteilungsfunktion durch Integration über die Wahrscheinlichkeitsdichte berechnet: |
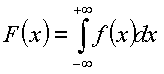 | |||||||
Wahrscheinlichkeit: Mit welcher Wahrscheinlichkeit tritt ein Ereignis aus der Anzahl möglichen Ereignisse ein? | |||||||
| |||||||
Im ersten Beispiel ist der objektive Charakter deutlich erkennbar und im zweiten Beispiel, der subjektive durch die “Alltagsaussage /-annahme” ebenfalls. | |||||||
Wahrscheinlichkeit: Vertrauens- und Irrtumwahrscheinlichkeit | |||||||
Wahrscheinlichkeiten:
P(Zahl) = Ereignis / mögliche Ereignisse = 1/2 = 0,5 (50%) Wir nehmen eine A-priori-Wahrscheinlichkeit P von P = 0,5 an! P(Zahl) = Anzahl Ereignis Zahl / Anzahl der Münzwürfe = 50 / 100 = 0,5 Hier sind wir von dem idealen Fall der Gleichverteilung zwischen Wappen und Zahl ausgegangen. In der “realen” Welt, strebt die relative Häufigkeit des Wurfs Zahl gegen die wahre Verteilung zwischen Wappen und Zahl mit steigender Anzahl n der Münzwürfe. Darauf basierend, lässt sich allgemein folgender Grenzwert für die A-posteriori-Wahrscheinlichkeit definieren:
|
Für die (logischen) Aussagen A und B werden die Verknüpfungen gemäß folgender Wahrheitswerttafel mit w = wahr und f = falsch erklärt: |
|
Lebensdauerverteilungen lassen sich die Weibullverteilung darstellen, mehr dazu hier...! | |||||
Istwert (actual value): Ermittlungsergebnis eines quantitativen Merkmals. Sollwert (desired value): Wert eines quantitativen Merkmals, von dem die Istwerte dieses Merkmals so wenig wie möglich abweichen sollen (siehe Toleranzbereich). Richtwert (standard value): Wert eines quantitativen Merkmals, dessen Einhaltung durch die Istwerte empfohlen wird, ohne dass Grenzwerte vorgegeben sind. Grenzwert (limiting value): Mindestwert oder Höchstwert. Mindestwert (lower limiting value): Kleinster zugelassener Wert eines quantitativen Merkmals. Höchstwert (upper limiting value): Größter zugelassener Wert eines quantitativen Merkmals. | |||||
Wiederholpräzision (repeatability, wirhin-run precision): Die Wiederholpräzision ist die Bezeichnung für das Ausmaß der gegenseitigen Annäherung der Prüfergebnisse unter Wiederholbedingungen. | |||||
Bei der Gewinnung von unabhängigen Prüfergebnissen gelten folgende Bedingungen: festgelegte Prüfmethode, identisches Objekt (Material), der gleiche Prüfer (Beobachter), die gleiche Prüfausstattung (Geräte) und der gleiche Ort (Labor). | |||||
Qualitätsprüfung nach für die Wiederkehr vorgegebenen Regeln in einer Folge von vorgesehenen Qualitätsprüfungen an derselben Einheit (Lot, Charge). | |||||
Qualitätsprüfung nach unerwünschtem Ergebnis der vorausgegangenen in einer Folge von zugelassenen Qualitätsprüfungen an derselben Einheit (Lot, Charge). | |||||
Wilcoxon-Test: Tests für den Vergleich zweier verbundener Stichproben, Vorzeichen-Rang-Test nach Wilcoxon. |
Wölbung: Siehe Abweichung von der Normalverteilung. |
Oft
besteht die Notwendigkeit Merkmalswerte (Merkmalsausprägungen) zur besseren Beurteilung oder für statistische Verfahren derart zu normieren, dass der Mittelwert den Wert 0 und die Standardabweichung den Wert 1 annimmt. Diese Standardisierung oder Z-Normierung wird über folgende Formel durchgeführt: |
Zahlen, hier eine Übersicht über die Einteilung der Zahlen. |
Zahlen, Das Gesetz der Großen - : Das Gesetz der Großen Zahlen wird am Beispiel des arithmetischen Mittels dargestellt:
|
|
|
Strebt nun n -> E( Einfach ausgedrückt, bedeutet dies, dass mit einer hohen Anzahl von Werten, die Schätzung des Mittelwerts der Merkmalausprägung In diesem Beispiel sagt das Gesetz der großen Zahlen aus, dass mit dem Streben von n -> |
| |||||||||||||||||
Zeitreihenanalyse siehe hier! |
In der Zeitreihenanalyse wird davon ausgegangen, dass die Beobachtungen Xt eines zufälligen Prozesses zu verschiedenen Zeitpunkten tn voneinander abhängen. Diese Beobachtungen folgen einer bestimmten Verteilung, die im Allgemeinem unbekannt ist. Die Beobachtung Xt stellt eine Ausprägung des Merkmals X zum Zeitpunkt t dar und somit kann nicht auf die Momente Erwartungswert und Varianz geschlossen werden. Ein statistischer Prozess Prozess (dem die Zeitreihe zugrunde liegt) wird als schwach stationär bezeichnet, wenn der Mittelwert und die Varianz zeitunabhängig sind und die Kovarianz lediglich vom zeitlichen Abstand (Lag) zwischen den Punkten t und t+1 abhängt, aber nicht vom Zeitpunkt t an dem die Beobachtung X gemacht wird. Von einem streng stationären Prozess wird gesprochen, wenn zu jedem Zeitpunkt t die gleiche Verteilung vorliegt. Verlieren Sie bezüglich der Stationarität nicht die Eingangsbemerkung aus den Augen! |
Zeitreihe, weißes Rauschen (White noise) In der Zeitreihenanalyse wird das weiße Rauschen als der einfachste statistische Zeitreihen-Prozess betrachtet. Das weiße Rauschen besteht aus zeitlich zufälligen, unkorrelierten Beobachtungen mit dem Erwartungswert Null und einer konstanten Varianz. Dieser Prozess ist schwach stationär. Die Autokorrelationsfunktion ist immer Null, ausgenommen für Lag = 0. Für den Prozess „weißes Rauschen“ kann keine Aussage über den zukünftigen Verlauf des Prozesses aus der Vergangenheit gemacht werden, da die Autokorrelationsfunktion keine Struktur aufweist. |
Zwischenprüfung: Qualitätsprüfung während der Realisierung einer Einheit (Lot, Charge). | ||||
Zufällige Abweichung (random deviation, random error): Zufällige Abweichungen weisen bei definierter Vorgehensweise (z. B. gleiche Prüfmethode) ein zufälliges Ausmaß und Vorzeichen auf. Bei quantitativen Merkmalswerten ist die zufällige Abweichung, unter Berücksichtigung der vorangemachten Ausage, gleich der Differenz aus Merkmalswert und richtigem bzw. wahrem Wert. | ||||
Zufallsstichproben sind Teile einer Grundgesamtheit, die durch einen Auswahlprozess mit Zufallsprinzip aus dieser entnommen und stellvertretend, repräsentativ für die Grundgesamtheit sind (siehe Grundgesamtheit und Beispiel). | ||||
Die Zufallsvariable ist ein Grundbegriff der Statistik mit folgender Bedeutung: Der Wert einer Zufallsvariablen, z. B. ein Merkmalswert, wird bei der Durchführung eines Versuches ermittelt (siehe auch Zufallsvorgang). Je nach Art des Versuchs (Experiment, Beobachtung) sind die möglichen Werte der Zufallsvariablen ein einzelner Wert einer Größe (beim Messen), einer Zahl (beim Zählen), eine Ausprägung (bei der Bestimmung eines qualitativen Merkmals) usw. oder auch Paare, Tripel, Quadrupel, n-Tupel solcher Werte. Eine Zufallsvariable, die nur abzählbar viele Werte annehmen kann, heißt “diskrete Zufallsvariable”. Eine Zufallsvariable, die kontinuierliche Werte annehmen kann, heißt “kontinuierliche Zufallsvariable”. | ||||
Bevor dieser Vorgang durchgeführt wird, ist es ungewiss, welches Ergebnis tatsächlich eintreten wird (siehe Zufallsvariable -> Durchführung eines Versuchs). Dieses Ergebnis wird mit einer bestimmten Wahrscheinlichkeit eintreffen. | ||||
Zuverlässigkeitsuntersuchungen: Zum Thema Zuverlässigkeitsuntersuchung (Lebensdauer-) siehe Weibullverteilung! | ||||
Literaturstellen: (Zurück...) |
Wenn Sie möchten, können Sie Ihre Literatur direkt über diesen Link bei Amazon beschaffen! Ihre Bestellung trägt zum Erhalt und zur Weiterentwicklung dieser Seiten bei! Danke! |
Hat der Inhalt Ihnen weitergeholfen und Sie möchten diese Seiten unterstützen? |









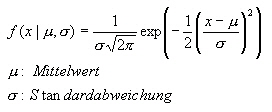 Form und Lage der Dichtekurve wird durch den Mittelwert und der Standardabweichung festgelegt
. Der Mittelwert liegt im Zentrum der Verteilung (= Maximum der Verteilung) und die Dichtekurve ist um so
Form und Lage der Dichtekurve wird durch den Mittelwert und der Standardabweichung festgelegt
. Der Mittelwert liegt im Zentrum der Verteilung (= Maximum der Verteilung) und die Dichtekurve ist um so