|
Logistische Regression | |||
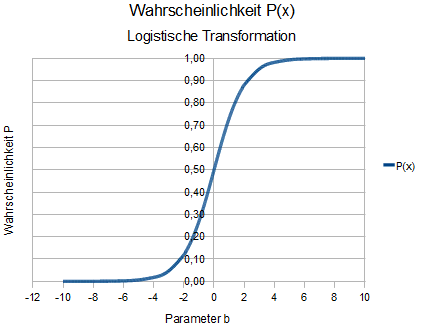
Methodisch gehÃķrt die logistische Regression zu den strukturprÞfenden Verfahren und hat eine verwandtschaftliche Beziehung zur Diskriminanzanalyse und natÞrlich zur Regressionsanalyse. Kann die ZielgrÃķÃe Y (abhÃĪngige Variable) nur eine binÃĪre (dichotome Verteilung) oder allgemein eine diskrete AusprÃĪgung, z. B. yi = 1 (fÞr Erfolg oder wahr oder ...) oder annehmen, kann die unter lineare Regression dargestellte Methode nicht angewendet werden. Dieser Regressionsansatz wÞrde Werte fÞr die abhÃĪngige Variable (ZielgrÃķÃe) yi < 0 und yi > 1 erlauben. Hier kommt das Verfahren der logistischen Regression zur Anwendung. Ãber die logistische Regression wird geschÃĪtzt, mit welcher Erfolgswahrscheinlichkeit P ein Ereignis Y, das Eintreten von Erfolg oder Misserfolg, von der/den unabhÃĪngige(n) Variablen X1 und X2 (oder allgemein von X1, ..., Xn) abhÃĪngt. Der Modellansatz nach P = a + bx beinhaltet die Herausforderung, dass die Wahrscheinlichkeit P, wie bekannt, nur zwischen 0 <= P <= 1 liegen kann. Ãber die logistische Transformation (F1) werden die Funktionswerte auf diesen Bereich begrenzt: |
|
| ||||||||||||||||||||||||||||
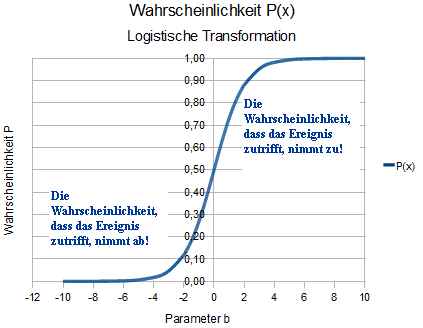
Ist die Wahrscheinlichkeit P = 0,5, hat das Merkmal X keinen Einfluss auf die Erfolgswahrscheinlichkeit des Ereignisses Y. D. h., ob das Ereignis Y auftritt oder nicht, hÃĪngt nicht von X ab! Die folgende Grafik beschreibt diese Aussage: |
 |
Ãber die logistische Transformation kann der obige Modellansatz linearisiert werden (Linkfunktion Logit): log(P(x)) = a + bx Die SchÃĪtzung der Parameter a und b erfolgt nach der Maximum-Likelihood-Methode. Um den rechnerischen Aufwand gering zu halten, wird allerdings das Statistikprogramm R zur SchÃĪtzung bemÞht. Zur SchÃĪtzung der Parameter a und b wird die Funktion glm() (GLM: Generalisierte lineare Modelle) mit exponentielle Verteilungsmodelle verwendet. |
|
|
Nun schÃĪtzen wir Þber die Funktion glm() die Parameter a und b und legen das geschÃĪtzte Modell im R-Objekt Ergebnis ab: > Ergebnis <- glm(Zustand ~ Temp, family = binomial("logit")) Unter family wird das exponentielle Verteilungsmodell Binomial und logit (Linkfunktion) angegeben. Þber die Funktion coef() lassen wir uns die Parameter a (= Intercept) und b (= Temp) ausgeben: > coef(Ergebnis) Ãber beide Parameter lÃĪsst sich durch Einsetzen in F1 die Eintrittswahrscheinlichkeit schÃĪtzen, ob die Gummidichtung bei z. B. -0,6 Grad Celsius (= 31 Grad Fahrenheit) ihre Bestimmung aufgibt, also undicht wird: |
Nach diesem Modell liegt die Ausfallwahrscheinlichkeit der Gummidichtung bei 99,96%! | ||||||||||||
Eine KenngrÃķÃenzusammenfassung erhalten Sie Þber die R-Funktion summary(): > summary(Ergebnis)
| ||||||||||||
AuffÃĪllig sind die KenngrÃķÃen zu Deviance Residuals (Deviance: Abweichung, frz. “dÃĐvier”) und zu den Koeffizienten (Coefficients), hier der Standardfehler (Std. Error)! Das geschÃĪtzte Modell haben wir im R-Objekt Ergebnis abgelegt. Darauf basierend kÃķnnen wir eine Prognose hinsichtlich der ZielgrÃķÃe Y, also der Eintrittwahrscheinlichkeit in Bezug einer bestimmten Temperatur, durchfÞhren. Dazu werden wir die R-Funktion predict() verwenden. Zuerst legen wir einen Datensatz Þber die Vorhersagetemperatur an: > T.min = 20 # Grad Fahrenheit
Nun wird die Prognose Þber die Funktion predict() durchgefÞhrt: > Temp.Prognose <- predict(Ergebnis, Temp.Modell, type = "response") Hinweis zum Funktionsaufruf: Da wir glm-R-Objekte nutzen, mÞssen wir den type = “response” als predict-Attribut mitgeben (siehe predict.glm)! Lassen wir uns die Prognosetemperatur Temp.Prognose (d. h. die Wahrscheinlichkeiten P) gegen die Vorgabetemperatur Temp.X grafisch darstellen: > sunflowerplot(Temp, Zustand, main = "Darstellung der Prognose", xlab = "Temperatur", ylab = "Wahrscheinlichkeit P") | ||||||||||||
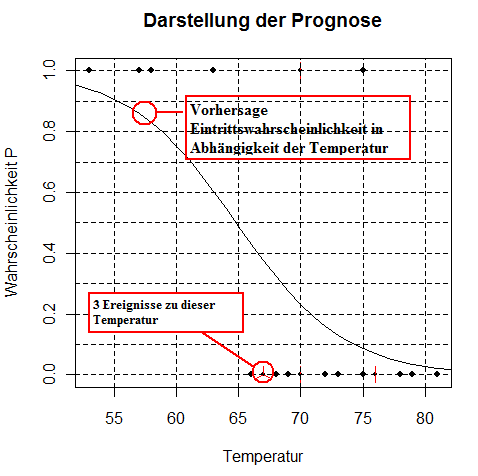 | ||||||||||||
Obige Grafik zeigt, je tiefer die Temperatur desto hÃķher die
Eintrittswahrscheinlichkeit, dass der Dichtungsring undicht wird. | ||||||||||||
Hat der Inhalt Ihnen weitergeholfen und Sie mÃķchten diese Seiten unterstÞtzen? | ||||||||||||