|
Diskriminanzanalyse | |||||
Als multivariates Verfahren ist die Diskriminanzanalyse eine Methode zur Untersuchung von Gruppenunterschieden. Mit dieser Analysemethode wird die Unterschiedlichkeit von zwei oder mehreren Gruppen hinsichtlich
ihrer Merkmale untersucht:
Als Beispiele kann die Gruppenzugehörigkeit (A- oder B-Qualität) über die Ausbeute eines Wirkstoffs von bestimmten Produktionsparametern abhängen, oder z. B. auch die Eigenschaften
bestimmter Automarken, welche die Kaufentscheidung der Kunden klassifiziert in Gruppen, beeinflussen, herangezogen werden. Bezüglich des Skalenniveaus entspricht die Gruppenzugehörigkeit einem nominalen Merkmal. Die klassifizierenden Merkmale (Parameter, Eigenschaften) entsprechem metrischen Niveau. Nachdem mit diesem Verfahren die Gruppenzugehörigkeit analysiert und durch ein Modell beschrieben wurde, ist sicher von Interesse, bei bekannten Merkmalen die Gruppenzugehörigkeit zu bestimmen. Als Beispiel soll ein neues Automodell auf den Markt gebracht werden. Dieses weißt bezüglich der im Modell berücksichtigten Merkmale bestimmte Ausprägungen auf. Auf Basis dieser Merkmalausprägungen sollten Sie nun über das Modell in der Lage sein, die Gruppenzugehörigkeit zu bestimmen. Im nachfolgenden Text, wird die Diskriminanzanalyse bis hin zur Gruppierung eines neuen Automodells beschrieben. Da dieses Verfahren ein sehr rechenintensives ist, wird zur Erleichterung R als Hilfsmittel eingesetzt. Auf dieser Seite wird das folgende 3-Gruppen-Beispiel über das R-Paket LinDA dargestellt. Die Diskriminanzanalyse startet mit der Definition der Gruppen. Die Gruppendefinition kann schon durch das Problem vorgegeben sein oder auf Basis eines Verfahrens wie z. B. der Clusteranalyse, beruhen. Zur Gruppendefinition wird natürlich die Anzahl der Gruppen (Gruppenanzahl g) festgelegt. Dabei ist das zur Verfügung stehende Datenmaterial zu berücksichtigen. Das bedeutet, dass
Mit der Diskriminanzanalyse wird auf Basis der Gruppen eine Trennfunktion oder auch Diskriminanzfunktion geschätzt: Wie weiter oben schon erwähnt, wird R unter Verwendung der Funktion lda() (Linear Discriminant Analysis, Paket MASS) zur Schätzung der Diskriminanzfunktion herangezogen. Die Funktion lda() schätzt dabei nicht nur die Diskriminanzfunktion, sondern erlaubt uns auch eine Wahrscheinlichkeitsaussage über die Gruppenzugehörigkeit der einzelnen Merkmalausprägungen. |
|
| ||||||||||||||||
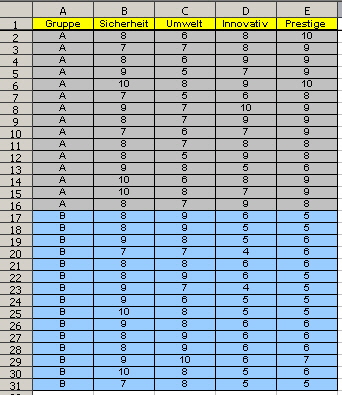
Um einen Überblick über die Gruppenmerkmale zu erhalten, wurde Bild 1 um die Gruppenmerkmalmittelwerte und deren Standardabweichung erweitert (Bild 2). Dadurch wird sicher vorstellbar, dass die Schätzung der Diskriminanzfunktion nicht nur von den Mittelwerten, sondern auch von der Standardabweichung abhängt. Der Unterschied zwischen den Gesamtmittelwerten (Schwerpunkt) über die beiden Gruppen (Bild 2 / Bild 3) stellt die Distanz dar. |
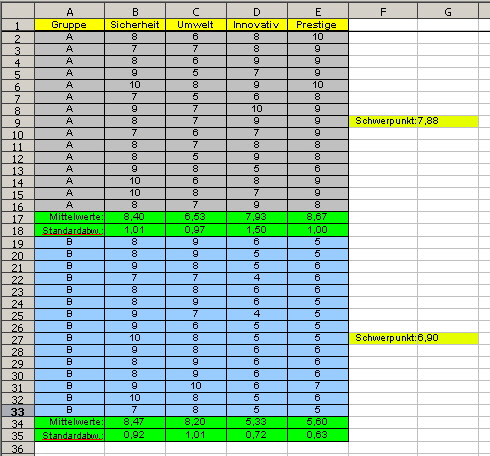 |
Bild 2: 2-Gruppen-Beispiel mit beschreibenden Daten |
|
| ||||||||||||||||
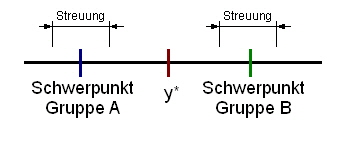
Idealerweise soll die geschätzte Diskriminanzfunktion optimal zwischen den Gruppen trennen. Diese Fähigkeit wird durch das Diskriminanzkriterium beschrieben. Wie schon angedeutet, wird das Diskriminanzkriterium durch die Streuung zwischen den Gruppen (erklärte Streuung) und durch die Streuung in den Gruppen (nicht erklärte Streuung) beeinflusst (siehe Zerlegung der Gesamtstreuung zum Thema ANOVA). In der nachfolgenden Schätzung der Diskriminanzfunktion wird Ihnen auffallen, dass das konstante Glied b0 nicht ausgegeben wird. Dies ist im Zusammenhang mit dem kritischen Diskriminanzwert y* zu sehen, da dieser so gewählt wird, dass der Diskriminanzwert den Wert 0 erhält. Durch diese Skalenverschiebung (siehe Bild 3) ändert sich natürlich nicht die Streuung und hat somit keinen Einfluss auf das Diskriminanzkriterium. Kommen wir nun zum praktischen Teil, der Schätzung der Diskriminanzfunktion: Die Diskriminanzanalyse über die R-Funktion lda() des Paketes MASS erwartet einen Datensatz, der die Gruppen und Merkmale enthält. Dieser Datensatz wird hier beispielsweise in der Variable Daten abgelegt. Die Funktion lda() erwartet die Merkmale und Gruppe in einer getrennten Übergabe zum Funktionsaufruf: lda(Merkmale, Gruppe). Die Gruppe ist in der 1. Spalte und die Merkmalausprägungen in den Spalten 2 bis 5 abgelegt (siehe Funktionsaufruf). Der Funktionsaufruf mit dem Datensatz aus Bild 1 zeigt folgende Schätzung: |
|
| ||||||||||||||||||||
Die Koeffizienten (LD1) als Diskriminanzfunktion: y = b0 + b1x1 + b2x2 + ... + bjxj y = 0,0247*Sicherheit + 0.48228 * Umwelt -0.3038 * Innovation – 0.9031 * Prestige F2 |
lda(Daten[2:5], Daten[,1], CV = TRUE) $class $posterior | |||
Bild 5: Ausgabe der wahrscheinlichen Gruppenzugehörigkeit | |||
Sehen wir von der 12. Merkmalausprägung ab, gehören die ersten 15 Merkmalausprägungen deutlich zur Gruppe A, da die wahrscheinliche Zugehörigkeit über 99% beträgt (Ausgabe $posterior). Das gleiche trifft für die Zugehörigkeit der Merkmalausprägungen 16 bis 30 zur Gruppe B zu. Auch hier liegt die wahrscheinliche Zugehörigkeit bei > 99%. Für die 12. Merkmalausprägung wird auf Basis dieser Stichprobe (Befragung) deutlich eine Gruppenzugehörigkeit zur Gruppe B geschätzt! Dies wird nicht nur durch die $posterior-Ausgabe, sondern auch durch die $class-Ausgabe dargestellt (siehe farbliche Hervorhebung). Nach der Schätzung der Diskriminanzfunktion kann nun die Gruppierung (Klassifizierung) neuer Daten erfolgen. Es wird der Diskriminanzwert y nach F1 geschätzt und auf Basis des Resultates die Gruppierung durchgeführt. Dazu wird die R-Funktion predict() verwendet. Der Aufruf geschieht wie folgt: predict(Modell, Datensatz) Das Modell ist die Schätzung der Diskriminanzfunktion. Der Datensatz ist in diesem Beispiel das Datenobjekt Daten, wie oben schon erwähnt. Um den Funktionsaufruf übersichtlicher zu gestalten, wird das Diskriminanzfunktion-Modell in dem R-Objekt D.Funk abgelegt: D.Funk <- lda(Daten[2:5], Daten[,1]) Anschließend wird die Funktion predict() aufgerufen (Bild 6): |
|
| ||||||||||||
Haben Sie einen komplett neuen Datensatz, z. B. die Bewertungen Sicherheit = 5, Umwelt = 5, Innovation = 8 und Prestige = 8, sieht die Vorhersage wie folgt aus (Bild 7): |
|
|
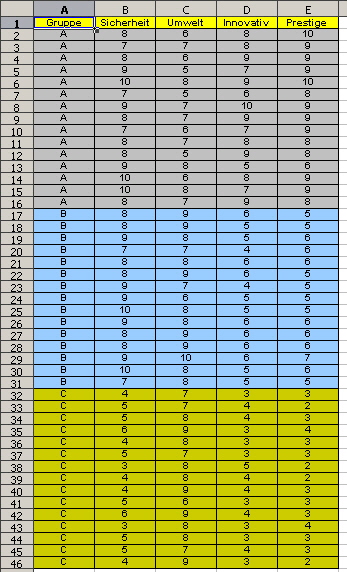
Diese Bewertung (Test) muss zur Gruppe A gerechnet werden. Wir erweitern das Beispiel um eine weitere Gruppe, der Gruppe C und kommen so zu einem 3-Gruppen-Beispiel (Bild 8): |
|
| ||||||||||||||||
|
|
Es werden 2 Diskriminanzfunktionen, LD1 und LD2, ausgegeben: y = b0 + b1x1 + b2x2 + ... + bjxj LD1: y = 0.4019*Sicherheit - 0.3378* Umwelt + 0.4077 * Innovation + 0.9035 * Prestige LD2: y = 0.8831*Sicherheit + 0.397* Umwelt - 0.2366 * Innovation - 0.327 * Prestige |
Möchten Sie die wahrscheinliche Gruppenzugehörigkeit ausgegeben bekommen, ergänzen Sie den lda-Funktionsaufruf wieder mit dem Argument CV=TRUE. Auch hier wird natürlich der 12. Datensatz der B-Gruppe als wahrscheinlicher zugeordnet. Auch hier möchte ich Ihnen die konstanten Glieder nicht vorenthalten: LD1 b0: -7,7653 Rufen Sie nun wie im 2-Gruppen-Beispiel die R-Schätzfunktion predict() zur Schätzung der Diskriminanzwerte y auf und Sie erhalten folgende Ausgabe (Bild 10): |
|
|
Bild 10: predict-Ausgabe |
Hier fällt die Übersicht über die Gruppen A, B und C nicht mehr so leicht wie im 2-Gruppen-Beispiel, da der “Separator” nun nicht nur einfach das Vorzeichen ist. In diesem Fall hilft eine R-Grafik weiter (Bild 11): |
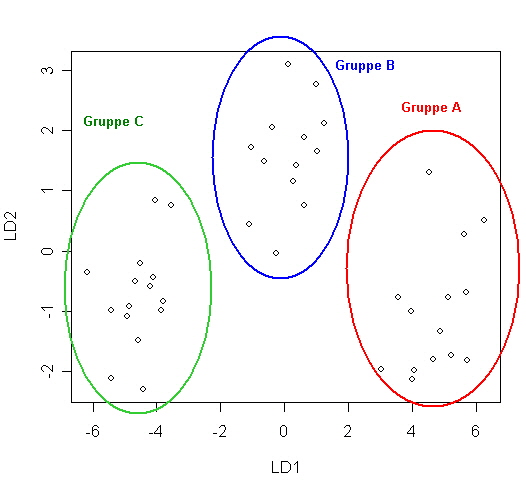 | ||||
Bild 11: Grafische Ausgabe geschätzten Diskriminanzwerte y | ||||
Für einen komplett neuen Datensatz, z. B. die Bewertungen Sicherheit = 5, Umwelt = 5, Innovation = 4 und Prestige = 5, sieht dann die Vorhersage wie folgt aus: Test <- c(5,5,4,5) predict(d.Funk,Test) | ||||
Die Ausgabe $posterior zeigt wieder die wahrscheinliche Gruppenzugehörigkeit an (mit 85%iger Wahrscheinlichkeit zur Gruppe C) und die Ausgabe $x die Diskriminanzwerte. Sie können obige Beispiele wie auf der Seite Diskriminanzanalyse mit dem R-Paket LinDA beschrieben nacharbeiten oder auch nur die Beispieldaten zu Ihrer eigenen Verwendung downloaden:
|
Hat der Inhalt Ihnen weitergeholfen und Sie möchten diese Seiten unterstützen? |