|
| |||||
Varianzanalyse (ANOVA) mit R | |||||
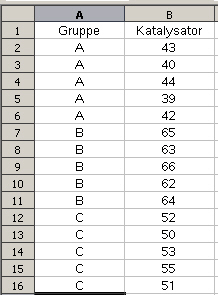
Die auf der Seite Varianzanalyse gezeigten Beispiele können mit R-Funktionen nachvollzogen werden. Wenn Ihnen R noch unbekannt ist, empfehle ich Ihnen zur Einarbeitung das Buch Einführung in R. Bevor wir mit den Standard-R-Funktionen die Varianzanalysen durchführen, möchte ich Ihnen die Funktion anova_faes darlegen, die den gezeigten Beispielen entspricht. Ich gehe von der Annahme aus, das die Funktion anova_faes in die R-Arbeitsumgebung geladen wurde. Zur einfaktoriellen Varianzanalyse wird als nächstes der entsprechende Beispieldatensatz (Einf_ANOVA_Daten) geladen: |
> Daten_einfach <- read.csv2("Einf_ANOVA_Daten.csv") |
Danach wird die Funktion anova_faes mit dem Datensatz Daten_einfach und dem Argument erweitert=TRUE, zur erweiterten Informationsausgabe, aufgerufen: > anova_faes(Daten_einfach, erweitert=TRUE) |
Um beispielhaft eine zweifaktorielle Faktorenanalyse durchzuführen, wird der Beispieldatensatz Zweif_ANOVA_Daten in die R-Arbeitsumgebung geladen: |
> Daten_zweif <- read.csv2("Zweif_ANOVA_Daten.csv") |
Die Funktion anova_faes wird wie im obigen Beispiel aufgerufen, wobei neben dem Datensatz Daten_zweif die Argumente zweif=TRUE (für zweifaktorielle ANOVA), n.i = 3 (für 3 Katalysatoren) und n.j = 2 (für 2 pH-Wert-Niveaus) mit übergeben werden: |
> anova_faes(Daten_zweif, zweif=TRUE, n.i=3, n.j=2, erw=T)
|
Hinweis zu Tabelle 18 siehe hier! |
|
| ||||||||||||
Die Daten aus Abb. 1 werden wieder beispielhaft in die R-Umgebung geladen: > Daten_einf <- read.csv2("Einf_ANOVA_Daten_2.csv") |
Zur Ausführung einer einfaktoriellen ANOVA muss zuerst ein Modell (ein R-Objekt) über die Funktion lm() berechnet werden: > Modell <- lm(Daten_einf$Katalysator ~ Daten_einf$Gruppe) | |||||
|
Dieses Modell wird dann der Funktion anova() übergeben und folgende Ausgabe auf der Konsole gemacht: > anova(Modell) | |||||